 Next generation library catalog
Next generation library catalog
This text outlines an idea for a "next generation" library catalog. In two sentences, this catalog is not really a catalog at all but more like a tool designed to make it easier for students to learn, teachers to instruct, and scholars to do research. It provides its intended audience with a more effective means for finding and using data and information.
Executive summary
People's expectations regarding search and access to information have dramatically changed with the advent of the Internet. Library online public access catalogs (OPAC's) have not kept up with these changes. The proposed "next generation" library catalog is an attempt to address this phenomenon. It's design less like a "catalog" -- an inventory list -- and more like a finding aid. It contains data as well as metadata, and it is bent on doing things with found items beyond listing and providing access to them. It is built using open standards, open source software, and open content in an effort to increase interoperability, modularity, and advocate the free sharing of ideas.
Technically speaking, this "next generation" library catalog is a database/index combination. The database is made up of XML files of various types: MODS, TEI, EAD, etc. The index is a full-text index supplemented with XML-specific elements as well as Dublin Core names. End-user access to the system will be through a number of searchable/browsable interfaces facilitated by SRW/U. Services against individual items from the interfaces (such as borrow, download, review, etc.) will be facilitated via OpenURL.
The implementation of this "next generation" library catalog is divided into a seven-step process:
- Allocate resources
- Answer questions regarding information architecture
- Conduct surveys, focus group interviews, and usability studies
- Create/maintain the "next generation" library catalog
- On a daily basis go to Step #4
- On a quarterly basis go to Step #3
- On an annual basis go to Step #1
(Comment on this section on the LITA Blog at http://tinyurl.com/gjbvc.)
Introduction
In library parlance, an OPAC is an "online public access catalog". The operative word in this phrase is "catalog". Traditionally speaking, the OPAC is thought of as an index to the things owned or licensed by a library. It is an electronic version of the venerable card catalog. As such it contains "cards" pointing to books, not the books themselves. It contains "cards" pointing to article indexes but not the articles themselves. Because libraries do not own them, library OPAC's, for the most part, do not contain pointers to Internet resources because they are too dynamic in nature to maintain. These things, along with the bibliographic indexes, are relegated to a library's website, which, in turn, becomes information silos. Metasearch technology has tried to bring these things together under one search interface but with little success. As a catalog, OPAC's are akin to inventory lists allowing people to search for and identify things in or available from libraries. Beyond identification, OPAC's do not provide very many services against holdings besides the ability to borrow.
The OPAC should not be equated with an ILS -- the integrated library system. The ILS is a suite of software automating much of the traditional processes of librarianship. For example, there are circulation modules enabling libraries to keep track of who has borrowed what. There are acquisition modules allowing bibliographers to keep track of how much money they have spent and allows other people to do the actual purchasing. There are cataloging modules enabling catalogers to create MARC records and supplement them with controlled vocabularies and authority lists. Other modules provide functionality for interlibrary loan, the reserve book room, serials acquisitions, etc. The OPAC is the public face of a library, and in the big picture, it is traditionally an additional module in the ILS.
In the past decade people's expectations regarding search and the access to information have dramatically changed. The proliferation of desktop computers, the increasing amount of content "born digital", and the advent of the Internet have all contributed to this phenomenon. People expect to enter one or two words (or maybe a phrase) into a search box, click a button, get a list of relevancy ranks results returned, select an item from the results, and view/download the information. The process is quick, easy, and immediate. Even though people know the information available from libraries is free and authoritative they often use libraries as a last resort because they see library systems are overwhelmingly associated with books, confusing, difficult to use, time consuming, and inconvenient.
The proposed "next generation" library catalog is intended to address the issues outlined above. It builds on the good work previously done by the library profession through collection, preservation, organization, and dissemination. It takes into account the changing nature of user expectations and tries to meet them. It exploits computer technology and harnesses the knowledge built up by the information retrieval and digital library communities. The goal of the "next generation" library catalog is to create a transparent system enabling library users to get their work done more quickly and efficiently. It will not be seen as an impediment to learning, teaching, and scholarship, but rather as useful tool for getting an education and increasing the sphere of knowledge.
Assumptions
As the saying goes, "There is more than one way to skin a cat." Similarly, there will be no such thing as the "next generation" library catalog, only variations on a theme. Each implementation of a "next generation" library catalog will by slightly different, and the differences will probably be rooted in the individual implementation's underlying assumptions. There are a number of assumptions underlying the design of this particular "next generation" library catalog, and they are enumerated below.
It is not a catalog
The "next generation" library catalog is not a catalog, per se.
The "next generation" library catalog is not intended to be searchable list of the things a library owns or licenses. It is more than that. It is a list of the things deemed useful for achieving the goals of the library's parent organization. The world of information has moved beyond books, magazines, and videos. The computers and the Internet has spawned mailing lists (full of names, addresses, and telephone numbers), data sets, images, full-text books and journal articles, archival finding aids, pre-prints & other gray literature, etc. To various degrees all of these things are important to meeting the needs of library users. To the best of its ability, the "next generation" library catalog includes the full-text of these items or at least metadata describing these items in its collection.
It avoids multiple databases
The "next generation" library catalog avoids multiple databases and indexes, thus increasing simplicity and reducing the problem of de-duplication.
Multiple databases and multiple indexes increase complexity and necessitate an increase in computer infrastructure. They create information silos and make it challenging to create holistic systems. By avoiding the creation of multiple databases and indexes it will be easier to do global searching and refinement. Reducing information overload after returning too many hits will be overcome through the use of faceted browsing, an "intelligent" user interface, and the ability to create tightly focused queries against the index.
It is bent on providing services against search results
The "next generation" library catalog's user interface is bent on doing things with found items beyond listing and providing access to them. Again, the "next generation" library catalog is not a catalog but a tool.
Just think of all the things you can do with a physical book. You can place a hold on it. You can request it for document delivery (borrow it). You can renew it. With a tiny bit of work we could turn the book's metadata into a Chicago style citation for inclusion in a paper. We could allow people to review the book. We could allow people to purchase the book from a bookstore. Many of the same things can be applied to printed journal articles, but electronic journal articles are a different story. They lend themselves to a greater number of services such as download, print, save, annotate, index along with a set of other downloaded things. With adequate metadata it would be relatively easy to feed a system a book or journal article and request a list of possible email addresses for the author.
Put another way, the "next generation" library catalog provides services against items in its collection. These are value-added services provided by the library, and in turn, saving the time of the reader and making them more productive.
It is built using things open
This "next generation" library catalog is built using open standards, open source software, and open content in an effort to increase interoperability, modularity, and advocate the free sharing of ideas.
Librarianship is a highly collaborative profession. We share cataloging records. We jointly purchase/license materials. We share in the creation of collections. Our professional meetings measure in the 10's of thousands of people. Much of this is facilitated through the use of open standards like Z39.50, MARC, and AACR2. Hardware and software are crucial to the provision of the "next generation" library catalog, and it is a well-known fact that "given enough eyeballs, all bugs are shallow." Therefore open source software will be used in order to keep things transparent. Finally, open content such as articles from open access journals, full-text books from Project Gutenberg, theses & dissertations available from the Networked Digital Library of Theses and Dissertations, and preprints from open archives data repositories will be given priority in an effort to highlight advocate the use of information unencumbered by licensing agreements. This does not mean commercially available content will not be included, but access to the content or its metadata must be provided through some sort of open standard such as OAI-PMH or XML files.
(Comment on this section on the LITA Blog at http://tinyurl.com/lx8bh.)
Technological design
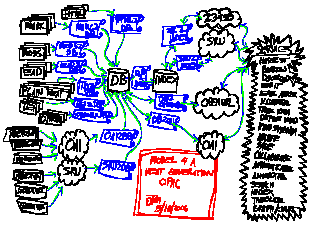
Model for a "next generation" library catalog |
{kind=link}
Technically speaking, this "next generation" library catalog is the combination of a relational database with a full-text index. Access to this database/index combination is provided through open standards such as Z39.50, SRW/U, OpenURL, and OAI-PMH.
Database
The database is designed to contain XML files enhanced with facet/term combinations. When at all possible these XML files (based on any DTD or XML schema) will represent a complete, atomic information resource such as a book marked-up in TEI or an article in XHTML. When it is impossible or impractical to acquire the full text of a resource, then a metadata record describing the resource will be used instead. In these cases MODS records, EAD files, or something like Dublin Core elements harvested from OAI repositories and packaged as RDF streams will be stored in the database.
The description of each XML record in the database will be enhanced with one or more facet/term combinations. The definition and creation of these combinations are left up to each library to articulate, but some facets might include: Formats, Audiences, Disciplines, XML Types, or Flags. Some example terms might include: Books, Journals, Articles, Freshman, Sophomores, Juniors, Astronomy, Music, Philosophy, MODS, TEI, RDF, Downloadable, Checked-out, or World-accessible.
Given this design, the database only contains four tables as illustrated by the following entity-relationship diagram:
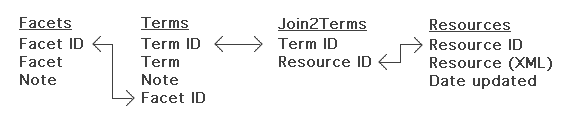
Entity-relationship diagram for the "next generation" library catalog |
Indexer
Databases are great for storing data and information, but, ironically, they are weak on finding data and information. Indexers are best used for facilitating search, and thus the need for an indexer in the "next generation" library catalog.
The entire content of each record in the database will be indexed. This means each record will be full-text searchable. To improve both precision and recall each record will also be indexed according it its most significant XML elements. Because the database will contain a wide variety of XML files represented by different DTD's and schemas, a best practices effort will be made to additionally map the XML elements to Dublin Core names. Using this approach records from the index should be accessible via free-text terms/phrases, DTD/schema-specific element names, as well as a set of commonly used fields represented by Dublin Core. At the very least the indexer is expected to support unicode and incremental updating. The native query language of the indexer is expected to support free-text, phrase, and field searching as well as Boolean operations, nested queries, right-hand truncation, stemming, sorting, and relevance ranking.
End-user access
End-user access to the database/index will be through standard protocols such as Z39.30, SRW/U, OpenURL, and OAI-PMH. Access to the system using their native interfaces is discouraged. While the use of the protocols may bypass some "kewl" features of the underlying database or search engine, they will enable the system to be more modular in nature. Such an approach will enable one indexer to be supplanted by another indexer with much greater ease. Similarly, when new databases become available or better protocol implementations are created the older tools can be replaced with their improved counter-parts.
This does not mean end-users will be expected to know the specific syntaxes of the abstract protocols in order to access the system. At the outset users will be presented with an HTML-based interface. From there they will be able to search and browse the system. Queries will be sent to the Z39.50 or SRW/U servers for processing and items will be returned supplemented with ways to expand and narrow the results. This search/browse process is repeated until the end-user identifies specific items of interest.
When an item from the search results is selected by the user an OpenURL is sent to a resolver. The resolver will return a list of functions -- services -- that can be applied against the item. Borrow. Download. Edit. Review. Annotate. Share. Delete. Index. Search. Find More Like This One. Discuss. Find author and email them. Create citation. Summarize. Write paper. Trace idea backwards. Trace idea forwards. Print. Email. Collaborate. Save. Archive. Translate. Show definition. Show synonym. Graph. Chart. Prioritize. Evaluate. Rate. Rank. Illustrate. Authenticate source. Etc. This list of services will be generated based on the characteristics of the item and represents a set of things the user can do with the item. For example, full-text articles are downloadable, and physical books are borrowable. The list of services is only limited by the time, energy, and imagination of the implementors.
(Comment on this section on the LITA Blog at http://tinyurl.com/zmlq2.)
Implementation: A Seven-step process
This section proposes a step-by-step approach for creating a "next generation" library catalog, but the process can be summarized in the following way:
- Allocate resources
- Answer questions regarding information architecture
- Conduct surveys, focus group interviews, and usability studies
- Create/maintain the "next generation" library catalog
- On a daily basis go to Step #4
- On a quarterly basis go to Step #3
- On an annual basis go to Step #1
1. Allocate resources
The "next generation" library catalog needs time, money, people with specific skills, and hardware to implement. This section outlines these things in greater detail.
You will need to assemble a team of people to do the work, unless of course Leonardo Di Vinci works in your library. Few people posses all of the necessary skills. At the very least your team will probably consist of a:
- systems administrator
- computer programmer
- graphic designer
- subject specialist
Systems administrator
The systems administrator is responsible for maintaining your computer's hardware, software, and networking infrastructure. They need to be knowledgeable about operating systems, filesystems, users/groups, and Internet connections.
Programmer
The programmer is responsible for creating functional interfaces to the underlying system. Some of these interfaces are computer-to-computer interfaces such as the importing of MARC records or processing SRU queries. Other interfaces will have human components, and in such cases the programmer will need to work closely with the graphic designer. It is essential for the programmer to be familiar with object-oriented programming techniques, XML along with Web Services computing, and common gateway interface (CGI) scripting.
Graphic designer
The graphic designer is responsible for making sure your human-to-computer interfaces are usable and aesthetically pleasing. (Usability is different from functionality.) They need to have an in-depth knowledge of HTML, XML, cascading stylesheets, and the principles of user-centered design. Ideally the user interfaces written by the programmer programmer will output rudimentary HTML with plenty of HTML class and id attributes to be used as hooks for the cascading stylesheets. Through the stylesheets the graphic designer should be able to modify the look & feel of the interface.
Subject specialist/librarian
Finally, the team will require someone who is knowledgeable about content, a subject specialist/librarian. This person will bring to the team the principles collection development, cataloging & classification, as well as reference services -- all of the traditional activities of librarianship. This person will be the primary driver behind the process of answering questions regarding information architecture, outlined below. Once the questions are answered, the subject specialist will be responsible for putting the answers into practice through data-entry. The subject specialist will need to articulate sets of facets and terms, select information resources, and enter everything into the system accordingly.
Other people
None of the people and skills outlined above are more important than the other. Each are equally necessary for a successful implementation. At the same time you might consider supplementing your team with people with more specialized skills such as:
- relational database design and implementation
- indexing techniques
- advanced XML applications and XSLT programming
- conducting surveys and doing statistical analysis
- facilitating focus group interviews and usability studies
- creating and maintaining controlled vocabularies
- doing large volumes of data-entry and maintenance
Computer hardware
Computer hardware/software and time are the necessary resources for the team to complete their implementation. The hardware/software requirements for implementing the "next generation" library catalog are directly proportional to the scope of the project. This particular implementation suggests purchasing a computer with as much RAM, CPU's, and hard disk space that $10,000 can buy and use to run Linux, a relational database, and an indexer.
Time
Time is by far the most expensive resource necessary to fully implement the "next generation" library catalog. Time will need to be allocated in a number of ways. First of all, time will need to be spent allowing the team members to actually become a team. Many people think this process is too "touchy-feely". On the other hand, the sooner the team establishes norms of behavior, decides how to build consensus, and learns how to work with each other the more quickly your implementation will come to fruition.
Second, time will need to be spent answering the questions of information architecture. On the surface this too appears to be a lot of "navel gazing" but time spent addressing these issues will uncover hidden assumptions, help you set priorities, outline the problems "next generation" library catalog is expected to address, and build relationships with your patrons. While this work does not produce a whole lot of tangible results, the result forms the entire foundation of your implementation.
Finally, time will need to be spent doing the work normally associated with the implementation of computer technology. Setting up hardware and software. Writing and/or configuring computer programs. Customizing interfaces to meet your specific needs. Filling the system with data. Maintaining the data. Evaluating success. Repeating the entire process. Here again, remember that any computer implementation consists of 20% computer work and 80% people work.
2. Answer questions regarding information architecture
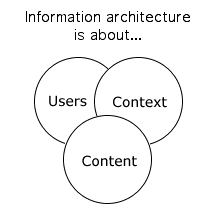
|
At its core, information architecture is about users, context, and content. By answering questions regarding these issues the "next generation" library catalog will not only be functional, but it will be understandable to the intended audience, serve a meaningful purpose, and contain relevant content. Once you answer the questions regarding users, context, and content, write down the answers. Use them as guidelines for a specific period of time (at least one year), and then regularly revisit the guidelines.
Users
The first step in designing an information architecture is answering questions regarding users. You need to define the primary audience of your information system, build relationships with them, and learn what they need and desire.
Defining your information system's primary audience is easier than you may think. In a private university like Notre Dame, the primary audience includes the University's students, faculty, and staff. The needs of these people take precedence over the needs of the general public, alumni, or scholars from other institutions. There are limited resources (time and money) allotted to the implementation of your information system, and it is not possible to be all things to all people.
After defining who your audience is, you need to establish inter-personal relationships with them. No, you don't have to become their best buddy, but you do need to build rapport to learn their expressed needs and desires. You need to learn and, more importantly, understand the challenges and difficulties they are having when it comes to doing their work. By building relationships with your primary audience you will learn these priorities and be able to focus your resources on making them easier to accomplish.
Context
The next step in articulating an information architecture is to answer questions regarding context. What is the purpose of your "next generation" library catalog, how does it fit within the totality of your institution's products and services, and what sorts of resources (time and money) are allotted to the system's development and maintenance?
Your "next generation" library catalog will not exist in a vacuum. It will be a reflection of its hosting institution, and in order for the information system to reflect well you will need to know the goals and priorities of your institution. For example, you need to know the purpose of the hosting institution. What problems is it trying to solve? How can your information system be expected to contribute to the solutions? Look to your institution's mission statement for answers. Here at Notre Dame the library's role is to help the students, faculty and staff of the University community do their learning, teaching, and scholarship.
The context of your "next generation" library catalog will also be tempered by the amount of resources allotted to its development and maintenance. These resources take the form of time, money, hardware, software, people, and expertise. The implementation and ongoing maintenance of your information system will require a diverse set of skills. None of which are necessarily more important than the other. The people with the necessary skills include subject experts, leaders of people, graphic designers, people who can mark up texts, knowledge workers who can organize content, usability experts, marketers, programmers, and systems administrators. The amount of time and energy these sorts of people can bring to the implementation of your information system is directly proportional to what your information system will enable people to do and do well.
Content
The third step in the creation of your information architecture is defining what content it will contain. This is akin to articulating a collection development policy.
Not even Google provides access to the totality of the world's content, and there is no reason to expect you to fill this role. Instead, focus on the answers regarding users and content to define the scope of your content. Ask yourself, "What are the strengths of my institution?" "To what degree does my collection need to be comprehensive, authoritative, up-to-date, written in a particular language, presented in an aesthetically pleasing manner, etc?" In other words, create a list of guidelines that your information resources need to embody in order to be a part of your collection. Just because a particular information resource is about a particular subject does not necessarily mean it is a good candidate.
3. Conduct surveys, focus group interviews, and usability studies
Doing information interviews, focus group interviews, and usability studies allows you to build relationships with your intended audience, and there are many ways to go about this.
Surveys
Surveys are the first thing that come to mind. They are relatively inexpensive. They can touch large numbers of people, and they are good for answering "what" types of questions. "What is your age?" "What do you like and what do you dislike about our present information system?" "If you could change one thing, what would it be?" The answers to survey questions often need to be short and succinct; few people are going to give you a lot of detail while answering survey questions. The results of surveys usually manifest themselves numerically and then get converted into graphs. Along the lines of surveys are log file analysis. By looking at the statistics captured by your staff as well as your present information systems, you will get an idea of what your audience uses. People will often say one thing and act differently. Log files help put this behavior into perspective.
Focus group interviews
The other side of surveys are focus group interviews, structured communication sessions used to learn about your audience's feelings. When compared to surveys, focus group interviews require a greater degree of interpersonal skills on the part of a facilitator. They touch fewer people than surveys and therefore are often times seen as more expensive. On the other hand, focus group interviews answer questions surveys don't answer, specifically "why" questions. "Why do you like this service as opposed to another?" "Why do you think it is important to for us to implement such and such feature?" "Why do you spend your time working in this particular manner?" Just like surveys, the focus group interview process ranges from the simplistic to the complex. It can be as simple as a one-on-one chat over coffee, or it can be as elaborate as a meeting of six to twelve homogeneous people who answer questions in a moderated setting by a professional facilitator.
Usability studies
Finally, there are usability studies. Few people like to conduct usability studies because this is where the inadequacies of their systems become most apparent.
Usability studies are used to test the functionality and inherent usefulness of your system. The process of conducting usability studies is not elaborate. First you will want to create a list of tasks you expect end-users to be able to accomplish using your site. Traditional tasks for a "next generation" library catalog will include something like "Find and print three scholarly articles on the topic of AIDS in third world countries." or "What is the call number of the book entitled Megatrends by John Naisbitt?" For each usability test there should be no more than five or six tasks to accomplish.
The next step is to have a handful of people try to do the tasks. The general consensus of the professional usability community is that you only need five or six testers. Sit them down. Emphasize that they are not being tested but the system. Watch the people do the tasks. Ask them to think out loud. Observer their behavior and do you best to record it.
After conducting the tests you will see what worked and what didn't work. You will be surprised. What you thought was intuitive turns out to be library jargon. What you thought was important turns out to be irrelevant to their needs. At the same time understand it is unrealistic to expect 100 percent of your users to be able to do 100 percent of your tasks. Nobody and no system are perfect. Take what you have observed to heart and make a sincere effort to resolve the problem.
4. Create/maintain the "next generation" library catalog
The following sections describe in more detail the process of creating and maintaining the database/index combination.
Add/update/delete content from the database
Assuming that any type of XML file can be added to the "next generation" library catalog, identify and collect the desired data. Examples will include MODS (MARC) records describing the things in traditional library catalogs. Other examples will include EAD files from archives, the full-text of journal articles in the form of XHTML files, and TEI documents. Additionally, consider harvesting content from OAI data repositories, packaging up the resulting Dublin Core elements, and creating RDF files. Extremely rudimentary XML files with only two elements (title and body) can be created from plain text documents.
For each type of XML file used as input, write routine that stores the file to the database and supplements the record with facet/term combinations. These facet/term combinations are intended to denote they type of XML being stored as well as other characteristics of the information resource. Is it a book, a journal, or an article. Is it freely available or licensed to a particular community. Is it electronic or borrowable. Etc.
During this ingesting process it might be necessary to do a bit of data normalization, but that should be kept to a minimum because such a process is not necessarily scalable nor cost-effective.
Index the content of the database
Make the content of the database searchable by indexing it.
On a regular basis query the database for new data or all the data of a particular kind. Determine the type of XML used to describe or embody the information resource and extract its most important characteristics based on the patron's point of view. This information will be embodied as the native XML elements. To the best of your ability, map these elements to (extended) Dublin Core element names (title, creator, description, subject, identifier, etc.). The use of the native XML elements will allow for specific searches. Dublin Core pseudonyms will make the system easier to use and provide global searching.
At this point it will be a good idea to consider supplementing the record with terms from controlled vocabularies and authority lists. This also might be a good time to statistically determine the "aboutness" of the record using techniques like TF-IDF. The addition of these controlled terms and calculated phrases will improve precision and recall during the search process.
Feed the indexer the necessary content. This includes the native XML element name/value pairs associated with Dublin Core labels, the facet/term combinations supplementing the XML, plus the full-text of the XML record itself. By doing so the indexer will facilitate fielded as well as full-text searching.
Implement searchable/browsable interfaces
After the index is generated, create a dictionary and thesaurus from the words found in the index. At the very least the dictionary will support features such as Did You Mean? by providing alternative spellings to words. The thesaurus will enable users with one way to Find More Like This One. Consider supplementing the most significant words in the dictionary with definitions. Search results can return these definitions and the system can be used as a dictionary. Put the names of people and places from your authority lists in the dictionary and supplement them with freely available biographies and encyclopedia articles. Consider enhancing the thesaurus with words from your controlled vocabulary and phrases important to your local community. The maintenance of the dictionary and thesaurus are opportunities for traditional technical services staff with cataloging and classification expertise.
The interface to the "next generation" library catalog is essentially search (because it is an index) supplemented by browse. Implement at least three types of search interfaces:
- Simple - This is the one box, one button "Googlesque" interface expected by so many people.
- Advanced - This is the many boxes, and many buttons approach to search. Query-by-example. Here the user will be able to limit by this, that, and the other thing and employ Boolean operators in order to create a more focused query.
- Power - This interface allows the user to enter command-like searches. Few people really enjoy these types of searches because they require a knowledge of the underlying system's underlying (CQL) syntax, but the expressiveness of such languages often returns very precise results.
By default, search results will be returned in relevancy ranked order, but this can be overridden by the user allowing the results to be sorted by author, title, date, popularity, etc.
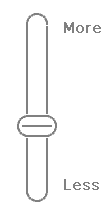
The Suggestion Widget |
The Suggestion Widget is an AJAX-enabled graphical slider associated with lists of alternative spellings and possible synonyms derived from previously entered search terms.
As the slider is moved higher and lower the number of suggestions visibly increases and decreases. |
Supplement the search results with functions from the dictionary and thesaurus. Recommend alternative searches based on similarly spelled words or thesaurus terms. Provide a way to increase or decrease the suggestion factor through the use of something like the Suggestion Widget.
Make it easy to "drill down" into search results by allowing the user to select facet/term combinations or author names from a sidebar. Provide a graphical view of the search results illustrating where large groupings of items reside.
Save queries during the user's session and allow them to be combined with each others or supplemented with additional queries. Allow people to do things with entire search results such as save them for future reference, used as part of a current awareness service, sent to an email address, or transformed into a bibliography using a particular bibliographic style.
Implement services against individual items
As end-users identify specific items of interest from search/browse process, implement services against those items and discover what those services are through OpenURL.
Each item in the search results will, at the very least, be associated with some sort of title and an identifier (key) from the underlying database. This information (as well as the identity of the end-user) can be repackaged as an OpenURL and submitted to a resolver. The resolver will look up the item in the "next generation" library catalog's database and generate a list services that can be applied against the item. This list of services will be based on things like the format of the information resource, the richness of its XML representation, the policies of hosting library, and privileges of the requester. Some of these services may be simply the display of detailed information regarding the item such as a MARC view, its call number, or availability for borrowing. Other services may be more interactive such as download, Find More Like This One, email, read/write review, email the author, save for future reference, etc. With additional computing power and know-how other more advanced and time-saving services could be implemented such as summarize this article, compare this article to others previously selected, get a list of people who have read this time and allow me to contact them, "tag" the item as in "folksonomies", annotate the item, etc.
Again, the "next generation" library catalog is not really a catalog but a tool enabling people to get information work done. The services of the "next generation" library catalog facilitate this process.
5. On a daily basis go to Step #4
As long as there is content useful to the library's primary audience there is a need to maintain the database, index, and user interfaces. Go to Step #4 everyday.
6. On a quarterly basis go to Step #3
Like the building of library collections and the provision of library reference services, software is never done, and it needs to be continually assessed. Go to Step #3 at least once every three months.
7. On an annual basis go to Step #1
Time, money, and people with the necessary skill are a limited resource. There will be a need to re-evaluate the effectiveness of the "next generation" library catalog compared to the library's parent organization. If proven effective, then the allocated resources "next generation" library catalog will need to be re-allocated. Go to Step #1 at least on an annual basis.
(Comment on this section on the LITA Blog at http://tinyurl.com/ktjwl.)
Conclusion
This is a very exciting time in Library Land. Never before has there been so much accessible content. Never before has there been so much computing power available at such low costs. Never before has there been such an overwhelming need from people for data and information. As long as the library profession does not limit itself to thinking about books, then what more could a librarian ask for?
The "next generation" library catalog is intended to be an evolutionary development. It is expected to build on the work already done by the library community, supplemented by the expertise of computer scientists, and driven by the expressed needs of library users. Libraries have often been described as the heart of colleges and universities. This was true because they contained the majority of the data and information needed to do learning, teaching, and scholarship. With the advent of globally networked computers used to create information "born digital" there has been a shift away from books towards smaller bits of electronic information. The "next generation" library catalog is a tool designed to fit into this shifting environment and move librarianship into a more active role when it comes to increasing the sphere of knowledge.
(Comment on this section on the LITA Blog at http://tinyurl.com/h4jop.)
Creator: Eric Lease Morgan <eric_morgan@infomotions.com>
Source: This essay was originally published serially on the LITA Blog at http://www.litablog.org/.
Date created: 2006-06-02
Date updated: 2007-12-27
Subject(s): next generation library catalogs;
URL: http://infomotions.com/musings/ngc/